Deployments, Containers and Orchestration
As applications scale up, we must determine a sane way of developing and deploying our applications.

Deployments can consume a lot of the developer's time. In this article we will compare the deployment styles in the past and present.
As applications get more complicated, we may choose to split up our applications into smaller applications as it is easier to scale horizontally instead of vertically. As such, we have to deeply understand the problems associated with distributed computing; how consensus is really difficult, what happens when we have a network partition, should I use a CP or a AP database, how should I respond when part of my application goes down, what if my server catches fire or if the power goes out in a particular data centre.
In this day and age, it's ludicrous to separate the operations from the development process since developers have to concern ourselves with these kinds of problems as applications outgrow the hardware we are presented with.
Big companies have put in their sweat and blood to produce tools to serve the entire planet. I will be touching on orchestration (Kubernetes) and containers (Docker) in this article. Solving problems associated with distributed computing isn't easy and tools like Docker and Kubernetes don't pretend that it will be easy either.
But to fully understand why these tools came up, lets turn back time and see how deployments were done in the past.
Traditional way
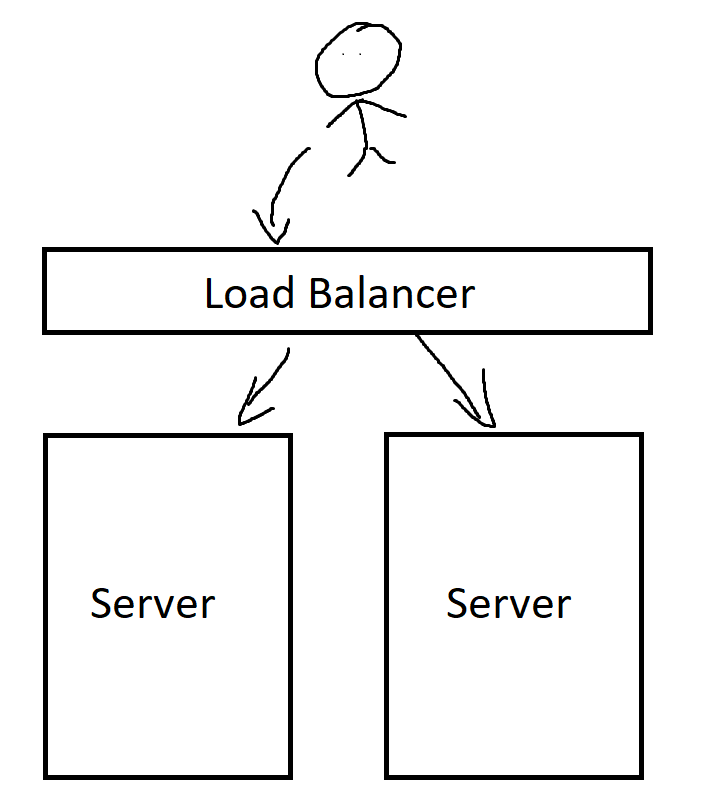
Deployment Process
rsyncorscpbinaries into machines.sshinto each machine.nohup <command to start> &to start process as a daemon.
Not very complicated for our needs in the past where applications were simple and monolithic. You could use a single machine or multiple machines attached to a load balancer and you are pretty much good to go.
Problems
- If your user base increases or there's a sudden surge, you could be dead in the water for weeks until you procure your new hardware to handle the extra load.
- After many iterations of your application, the application could demand extra resources and you would have to buy a bigger machine. Machine procurement could be really tricky in this situation.
- If your application is too small, you might still have to buy a machine that is oversized and you would have wasted the rest of it's capabilities.
- If you run multiple applications, you would have to make sure that the system binaries are compatible with both applications.
- Single point of failure.
- Managing machines by hand.
Virtual Machines (VM)
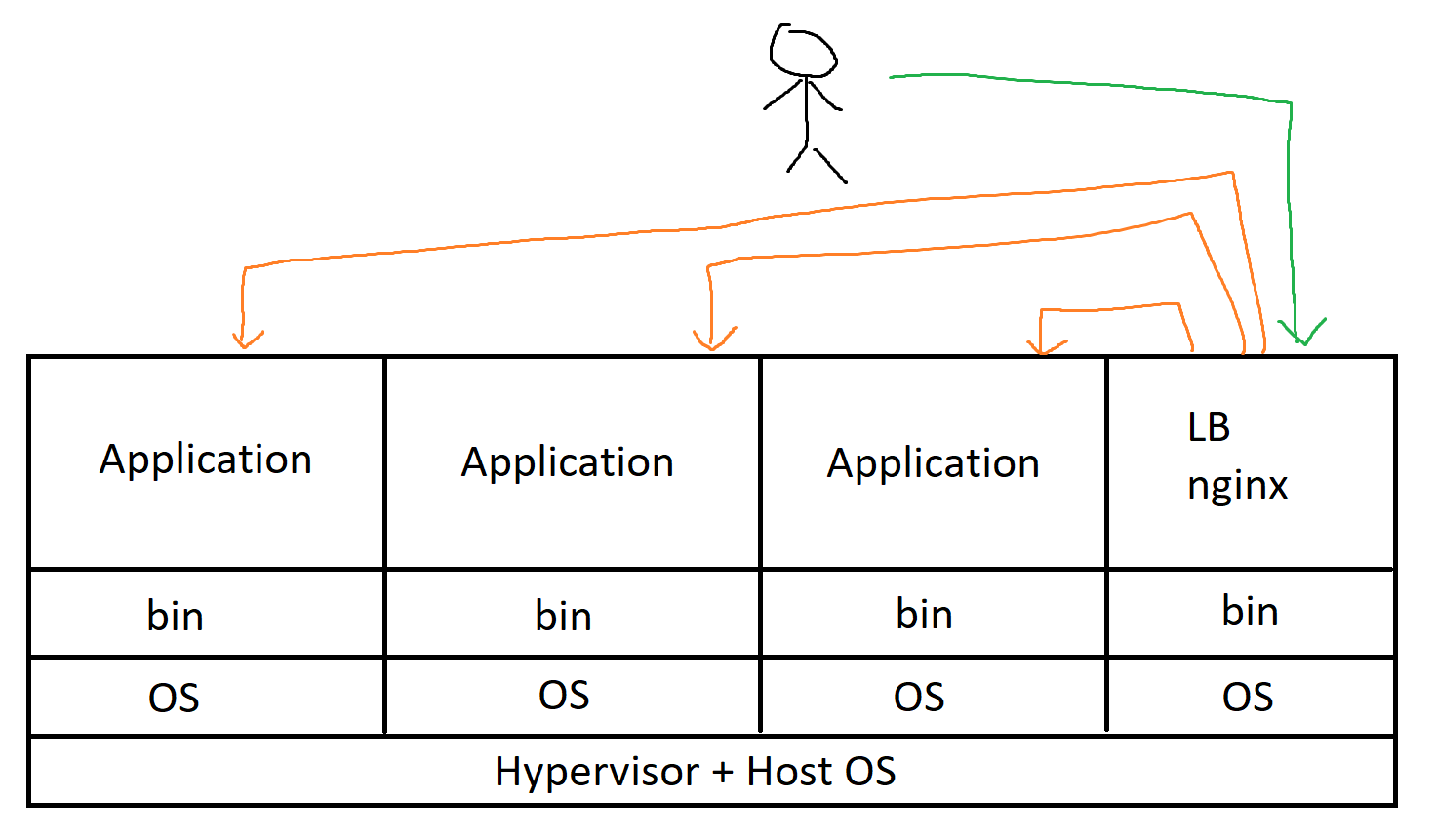
You could buy a big machine and provision whatever requirements you need. e.g. 2 CPUs and 4 gigs of ram for machine A, 4 CPUs and 8 gigs for ram for machine B etc. Alternatively, you could rent a server with the above requirements from a cloud provider. Cloud providers are really nice since you can leave the procurement of hardware, forget about dealing with hardware obsolescence and the other pesky things that come along with maintaining physical hardware, as well as hiring people to take care of your machines.
The deployment process is roughly the same as owning a physical machine. But instead of using a physical load balancer, you could use a L7 load balancer (like nginx), to balance the load between virtual machines.
Solves
- Wastage of resources if you were to deploy a small application.
- Provision only what you need (cloud specific), though not as granular as what we want if we are doing microservices.
- Able to cut up servers more easily, increased resource usage efficiency.
- Binary isolation within each virtual machine.
Problems
- Virtual machines are still pretty heavy weight and requires quite a bit of resources.
- If you app only requires 0.1 CPU and 200mb of ram, it's pretty hard to find a cloud provider who would provide that amount of ram, and impossible to get a VM with only 0.1 CPU.
- Still have a single point of failure (what if the bare metal machine fails, or the VM decides to throw a tantrum?)
- Managing machines by hand.
Containers (Docker) + VMs
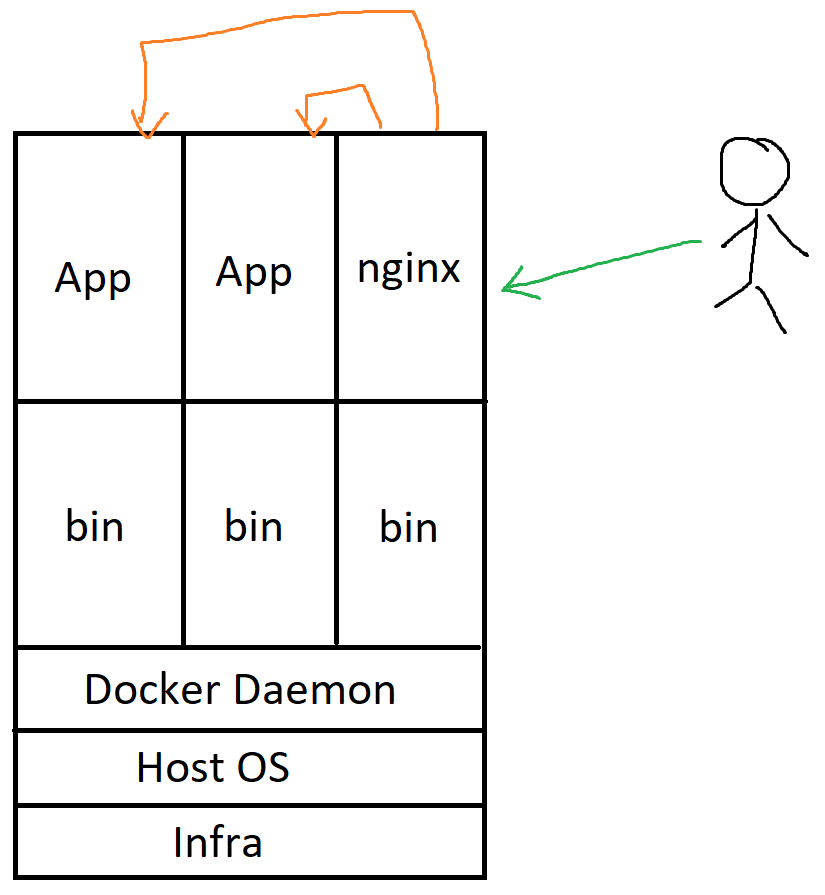
Instead of doing all your installations on the server by yourself during deployment time, you could package your system dependencies and your software binaries into a lightweight image called a container image. Think of this as a tightly sealed environment that is guaranteed to run as long as the machine has a Docker run time.
Deployment Process
- Write a Dockerfile with your desired application binaries and how to get your system dependencies.
- Build image.
- Tag image.
- Push to your desired Docker repository.
- Go into machine, pull image, run it as a container and voila your are up and running.
Solves
- "Works on my machine" excuses. Unified development and production environments.
- System dependencies isolation without spinning up another VM.
- Pack multiple applications to run in 1 VM, while benefitting from the isolation.
- Efficient use of resources.
- Extremely easy to roll back due to its immutable design; just pull your old container and replace it.
- Environment built at build time instead of deployment time. No more panic attacks when dealing one off configurations with production machines.
- If you have cgroups enabled, you can provision the amount of resources your app needs, like 0.5 CPU and 200mb of RAM.
Problems
- Networking between many containers can now be a real pain, especially when containers exists in different machines. So people generally write an nginx routing to expose the containers to other machines.
- Can still be quite troublesome to deploy into multiple machines.
- If you do have a lot of containers, it can be a challenge to bin pack across many machines if you run many containers.
- If you do have a lot of containers, it can be a challenge to make a lot of containers, keep track of which container runs in which machine by hand.
- You still have to own your VM in order to run containers safely as they do not sandbox the application completely.
Modern problems require modern solutions
Applications are getting bigger these days, and it's getting spread across multiple regions, machines and containers. Machines die all the time, software crashes, some shark decides to bite the underwater network cable. How do we deal with all of these and scale up without too much human intervention?
Pets vs Cattle
In the traditional ways of development, we have been treating our servers like pets, giving it names like Dewberry. If Dewberry goes down, the website stops functioning and that's bad for business. Everyone stops what they are doing and help resuscitate Dewberry.
In the newer ways of development, servers are named server-sg-001, server-sg-002, very much like how each cattle in a herd has a tag on them. When a server is misbehaving, it is killed, taken out of the fleet and replaced by another server.
Pets are servers that are hand fed, built and managed manually. They cannot be replaced easily and can never have any downtime.
Cattle are a fleet of servers that are built automatically. They are designed for failure and easily replaceable without human intervention. I will explain in further detail how Kubernetes treats its servers as cattle.
Container Orchestration with Kubernetes
Problem set
- I have 20+ services that I need to run.
- Each of them requires 2 - 10 copies of itself running, load balanced and communicate with each other.
- We should also be able to scale them up easily when there is a surge of traffic and vice versa.
- If a server dies, we want them to automatically spin up in another machine.
- It should efficiently bin pack the applications among all the machines.
- It should be able to monitor the health of the running applications, and spin up another instance if the application dies while running.
- We want each application to have its own set of isolated environment variables.
Kubernetes Objects
For the sake of brevity, I will not explain all the Kubernetes objects, but I will highlight the following:
Pod
The most basic unit in Kubernetes, it contains a group of containers and a group of volumes. Within the pod, Docker images share the same IP address and port space. To run multiple instances of an application, you spin up more pods of the same group of images.
Deployment
Pods are mortal creatures, if they die, they do not respawn. Unless you tell it to. Here's where deployments come in. You declare your desired number of pods to be run and you give your order to the Kubernetes master. Kubernetes will try to satisfy your requirements as much as possible. It will automatically schedule pods into whatever hardware you have without you needing to know where each pod goes into.
I have omitted the environment variables set into the deployment but you can set it in this file as well.
Sample deployment file that deploys nginx.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 5
maxSurge: 10
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
resources:
requests:
memory: "600M"
cpu: "400m"
limits:
memory: "1000M"
cpu: "600m"Once you have created the file, all you need to do is kubectl apply -f /path/to/deployment.yml. Lets break this down slowly:
Replicas: tells Kubernetes the amount of pods you want for this deployment.
Strategy: You can tell Kubernetes how you want your deployment rolled out. There's Recreate and RollingUpdate. Recreate only recreates a new pod after the pod goes down completely. RollingUpdate will make sure that a certain number of pods are alive at any one time when you are changing your pods. In this case, there are at least 5 pods alive (maxUnavailable) when you roll out, and a maximum of 20 pods running/terminating (maxSurge + replicas) running at once.
Resources: You can set limits on how much CPU/RAM your application requires. 1000M (millis) is equivalent to 1 CPU. This will help Kubernetes to bin pack your applications into nodes better.
For rolling updates, you can consider how the deployments will roll out.
- User says we need to upgrade our nginx container to a newer version, so we update
spec.template.spec.containers[0].imageto a newer version of the image. - We hit
kubectl apply -f /path/to/deployment.yml. - 5 pods get terminated (replicas - maxUnavailable). At the same time, 10 new pods get spun up with the new nginx pods. since we have require 10 new pods, and maxSurge allows for 10, we spin all of them at one go. (take home exercise: if maxsurge is 1, how does this deployment work out?)
- Since pods may take some time to spawn, for every one new pod ready to serve, it will terminate 1 of the old pods until those 5 disappears.
- Loop until the new pods are spun up and we are done with the deployment.
Service
Service is an abstraction for how other pods access each other. Generally, we don't want to deal with individual pods. Instead, we want them load balanced. So we hit the service if we want to call one of the microservice.
Sample deployment file that exposes our nginx service to our internal network.
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: NodePortPretty straightforward, there are different types here, there's ClusterIP, NodePort and LoadBalancer.
If all you need is for other pods to communicate with this service, ClusterIP would suffice.
If you require an external network to access it, you could use a NodePort and the service will expose a port you can hit. All you need to do is get the IP of any Node (basically the VM/machine running in the Kubernetes cluster) and hit its port and you will get access to any of the pods (load balanced).
LoadBalancer is implemented by the cloud provider. Kubernetes will inform your cloud provider you need an external IP and expose it to the rest of your cloud private infrastructure. If you require outside users (public) to access your services, you would need to provide an ingress rule which I will not cover here.
Putting them all together
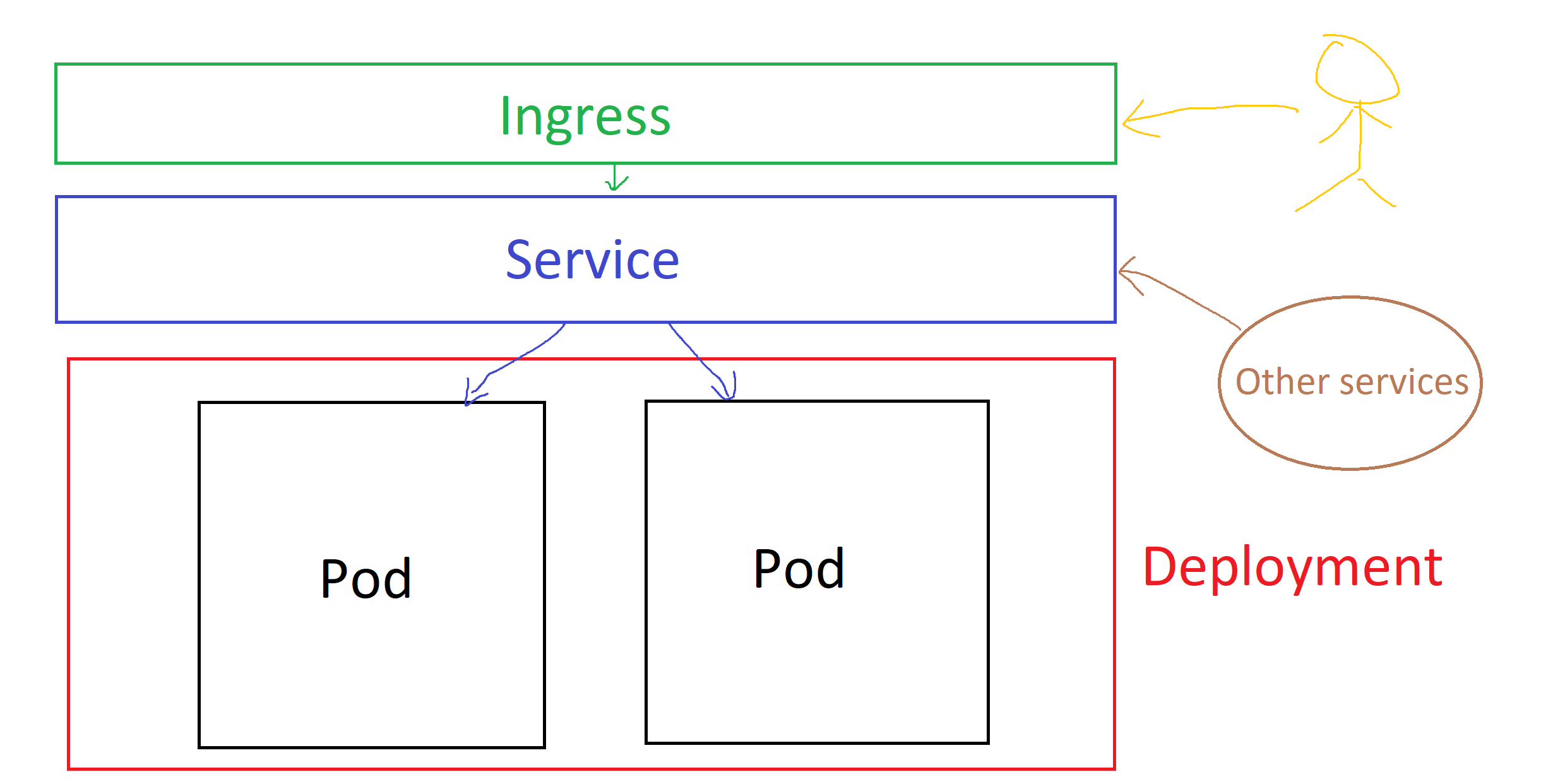
Although this picture doesn't show you where the pods live or the physical space, this shows the conceptual picture of how the services, deployments and pods work in unison.
Building and Orchestrating
Your CI/CD script may look like the following:
- Build docker image.
- Tag docker image.
- Push docker image into repo.
- Rename the image in the template deployment file.
- Apply the deployment file using
kubectl. - Apply the service file using
kubectl.
Fault handling
Kubernetes will try its best to faithfully follow your requirements should an unfortunate event occurs.
If a node goes down, if you use a cloud provider, they generally replace the server and spin it up for you again, and Kubernetes will automatically detect and repair itself, spinning up pods, moving pods around, until it gets to the desired state.
If a pod misbehaves, Kubernetes will nip it in the bud and spin up a new instance for you automatically.
Conclusion
I have only touched the surface of Kubernetes, there are many more things you can do with it, such as managing the network traffic between them by adding a service mesh, monitor logs and health statuses of your application via programmes such as Prometheus etc, or the other objects of Kubernetes such as secrets, config maps, cronjobs etc.
Developing web apps in this day and age can be a challenge when it comes to scaling. I have hit into walls at times and Kubernetes can be a real challenge to work with.
While Kubernetes sounds pretty good, it's important to know the problems it solves. Microservices, Docker and Kubernetes may not be what you need. If your app is small and does not require serving a lot of users, a monolith and a traditional approach may just suffice. Kubernetes solves large scale problems and you may not even need it!
Resources
Pets vs Cattle: http://cloudscaling.com/blog/cloud-computing/the-history-of-pets-vs-cattle/
Kubernetes: https://kubernetes.io/
Docker: https://www.docker.com/




{kind=link}